Introducing: AI content editor for Epi
About two months ago the blog post ‘Better Language Models and Their Implications’ came out. In case you heard nothing about it, researchers at OpenAI wrote a paper about a language model called GPT-2. The model is able to generate text that approaches the quality of human written texts. It is an interesting read and definitely food for thought. I had a laugh reading some of the generated texts:

Background vector created by freepik - www.freepik.com
SYSTEM PROMPT (HUMAN-WRITTEN)
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
MODEL COMPLETION (MACHINE-WRITTEN, 10 TRIES)
The scientist named the population, after their distinctive horn, Ovid’s Unicorn. These four-horned, silver-white unicorns were previously unknown to science.
Now, after almost two centuries, the mystery of what sparked this odd phenomenon is finally solved.
Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they found a small valley, with no other animals or humans. Pérez noticed that the valley had what appeared to be a natural fountain, surrounded by two peaks of rock and silver snow.”
Read more here - it’s quite funny
An article by The Guardian provided a couple of different examples, where they let the model generate text about itself, which seems shockingly legit to me as it’s also generating quotes and references (last paragraph of the following snippet).

I thought OpenAI’s paper was pretty cool and noticed that they put some code online.. It’s time to play!
Using GPT-2 to generate content
The OpenAI researchers decided not to release the full model or the dataset they used to train the model. They did however, release a smaller, pre-trained model we can use to generate text. Their repository can be found here and to my excitement (because I’m lazy when I can be) it includes two Dockerfiles that can be used to run the model locally. There are two ways you can use the model to generate text: conditionally or unconditionally.
- Conditionally: you will be prompted to enter an input text and the model will generate text based on the input
- Unconditionally: the model will generate random samples of text
In this post we’ll use conditional samples from the GPT-2 model and see how we can integrate it with Episervers AlloyDemoKit.
Architecture
As mentioned, the GPT-2 repository contains Dockerfiles to run the model. This is quite convenient because this way I don’t have to set up any of the requirements, like python or tensorflow, on my local machine. We will run the GPT-2 model as an “micro-service” which communicates using http requests (just a simple WebApi). A while ago I wrote about running Alloy in Docker, which is convenient as I can re-use it for this post and hook up the Alloy container to the GPT-2 container using service-to-service (container to container) communication.
The solution will consist of two containers, one running Alloy (on Windows) and one running the GPT-2 model (on Linux). We’ll let the GPT-2 container expose a simple web API which wraps around the code to generate conditional texts (albeit slightly modified). This will will allow us to do a request from the Alloy container to GPT-2 container and let the model generate text. note: I did rebuild docker with different memory constraints/defaults
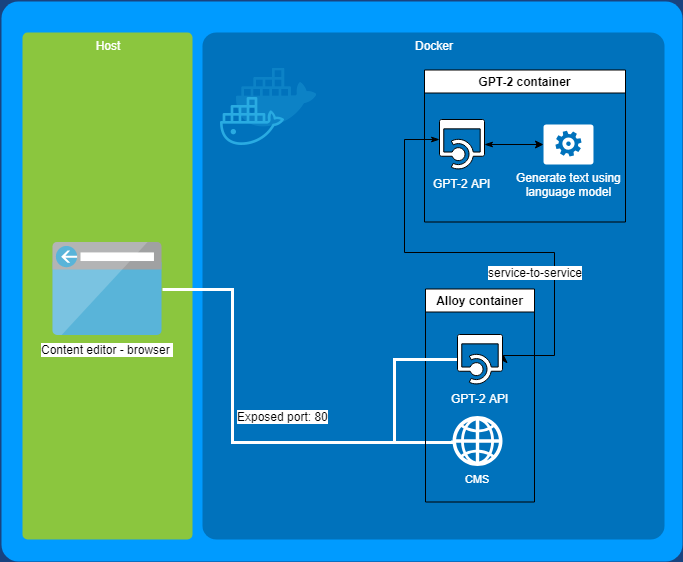
- Alloy
- Public web api - acts as a facade
- Does a request to GPT-2 web api
ContentEditorApiController–>/api/ai-contenteditor/please-finish-my?sentence={input}- Can be used to intercept / cleanup / throttle / add extra layer (queue)
- Add GPT-2 AI button to TinyMCE
- Uses existing content in TinyMCE editor
- Does a request to the
api/ai-contenteditor - Replaces content in editor with generated text
- Public web api - acts as a facade
- GPT-2
- Private web api (service-to-service communication)
http://alloydemokit-gpt-2:5000?input={input}- Generates text conditionally, based on input
- Private web api (service-to-service communication)
If you’re interested in the docker set-up, you can take a look at the docker-compose file, the Dockerfile for Alloy and the Dockerfile for GPT-2. Or you can clone the repo and run it yourself using VS.
Adding AI to the TinyMCE editor
In order to generate text conditionally, we will need input text. We’ll create a plugin for TinyMCE, this plugin will consist of nothing more than a simple button that uses the exiting content in the TinyMCE editor as input for the model.
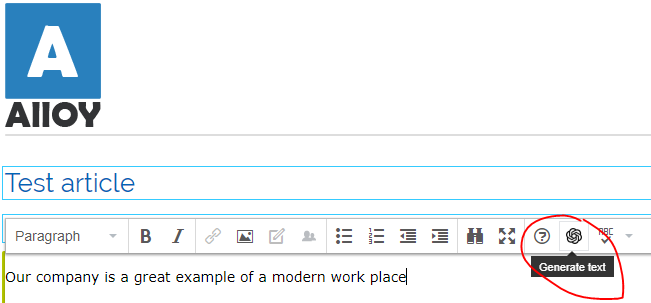
Creating a TinyMCE plugin is pretty easy, I’ve used the yeoman generator to scaffold a project.
yarn global add yo generator-tinymce
yo tinymce
? Package name: epi-tinymce-ai-plugin
? Add a description: Add AI capabilities to the TinyMCE editor
We now have a main/Plugin.ts to work with, it already provides an example of adding a button to the TinyMCE editor. We will extend it to read the current content in the editor, do a request to our content editor api and replaces the content with the result.
const setup = (editor: any, url: any) => {
editor.addButton('epi-tinymce-ai-plugin', {
tooltip: 'Generate text',
image: 'https://openai.com/favicon.png',
onclick: () => {
// Get input from TinyMCE editor
const input: string = editor.getBody().textContent;
if (input.startsWith(pleaseWaitMessage)) {
alert('Please wait a bit or remove the wait message.');
return;
}
// Init waiting state
const intervalId = startWait(editor);
// Do request
const inputUrl = getUrlFromInput(input);
fetch(inputUrl)
.then((response) => {
stopWait(editor, intervalId);
return response;
})
.then(checkResponse)
.then(useResponse(editor)) // Use response to populate TinyMCE editor
.catch(handleError(editor, input));
},
});
};
tinymce.PluginManager.add('epi-tinymce-ai-plugin', setup);
The full code for the plugin can be found here
The TinyMCE button will call the ContentEditorApiController, which in turn calls the api on the GPT-2 container. The ContentEditorApiController does some cleanup and returns the result back to the browser. The result is used to replace the TinyMCE editor content.
[RoutePrefix("api/ai-contenteditor")]
public class ContentEditorApiController : ApiController
{
private static readonly Lazy<HttpClient> LazyHttpClient = new Lazy<HttpClient>(() =>
new HttpClient { BaseAddress = new Uri("http://alloydemokit-gpt-2:5000") });
[HttpGet]
[Route("please-finish-my")]
public async Task<IHttpActionResult> Get(string sentence)
{
if (string.IsNullOrWhiteSpace(sentence))
{
return BadRequest(nameof(sentence));
}
var input = sentence.Trim();
var result = await LazyHttpClient.Value.GetStringAsync($"?input={input}");
// Use result up to <|endoftext|> (the rest seems to be random gibberish)
var cleanResult = result
.Split(new[] { "<|endoftext|>" }, StringSplitOptions.RemoveEmptyEntries)
.FirstOrDefault();
return Ok(new GeneratedContentResult
{
Input = input,
Result = result,
CleanResult = $"{input}{cleanResult}"
});
}
}
All there’s left is the GPT-2 web api, which is an API wrapper around the code for conditional text generation:
from flask import Flask
from flask import request
from generate_conditional import conditional
app = Flask(__name__)
@app.route('/')
def hello_world():
input = request.args.get('input')
top_k = request.args.get('top_k', 100, int)
return conditional(raw_text_input=input, top_k=int(top_k))
Python app here, slightly modified conditional method here as the provided example is a console application
Giving it a spin
Let’s put the AI content editor to work and feed it the first paragraph of this blog post:
SYSTEM PROMPT (HUMAN-WRITTEN)
About two months ago the blog post ‘Better Language Models and Their Implications’ came out. In case you heard nothing about it, researchers at OpenAI wrote a paper about a language model called GPT-2. The model is able to generate text that approaches the quality of human written texts. It is an interesting read and definitely food for thought. I had a laugh reading some of the generated texts:
MODEL COMPLETION (MACHINE-WRITTEN, 1 TRY)
these are wonderful examples of GPT-2’s natural learning. We have created it in Python by default but not once did we check out many variables around it (many of which could have been explained by reading the GPT-2 data). As a blog post from the future I want to take this opportunity and talk about the actual results of the GPT-2 model. The results.↵GPT-2 models are not perfect (which might be why there are so many comparisons to be made). For one thing, all the data generated by our data manipulation is quite small. (This means it has a small chance of being too narrow). You might also have to find some way to control GPT-2’s structure (one of the most important things in design is not to draw big numbers in that way in the book).
Or let’s have it create a list of requirements for our integration:
SYSTEM PROMPT (HUMAN-WRITTEN)
In order to achieve the most successful integration with an AI language model like GPT-2, you’ll have to make sure you meet the following three requirements:
MODEL COMPLETION (MACHINE-WRITTEN, 1 TRY) 1) Use your existing AI with the new version 2) Configure the newly installed GPT-2 firmware 3) Launch the latest version of your GPT-2 firmware on Ubuntu-based systems If you fail this latter step, the new version of your GPT-2 will be unable to implement the required methods of execution, either in /etc/init.d/gpt2 and /var/lib/gpt2/boot-all.2 as in /etc/init.d/gpt2 A new version of /etc/init.d should be created within the ‘default-options’ directory where things get complicated and if you do not have your existing GPT-2, your original kernel would be ignored.
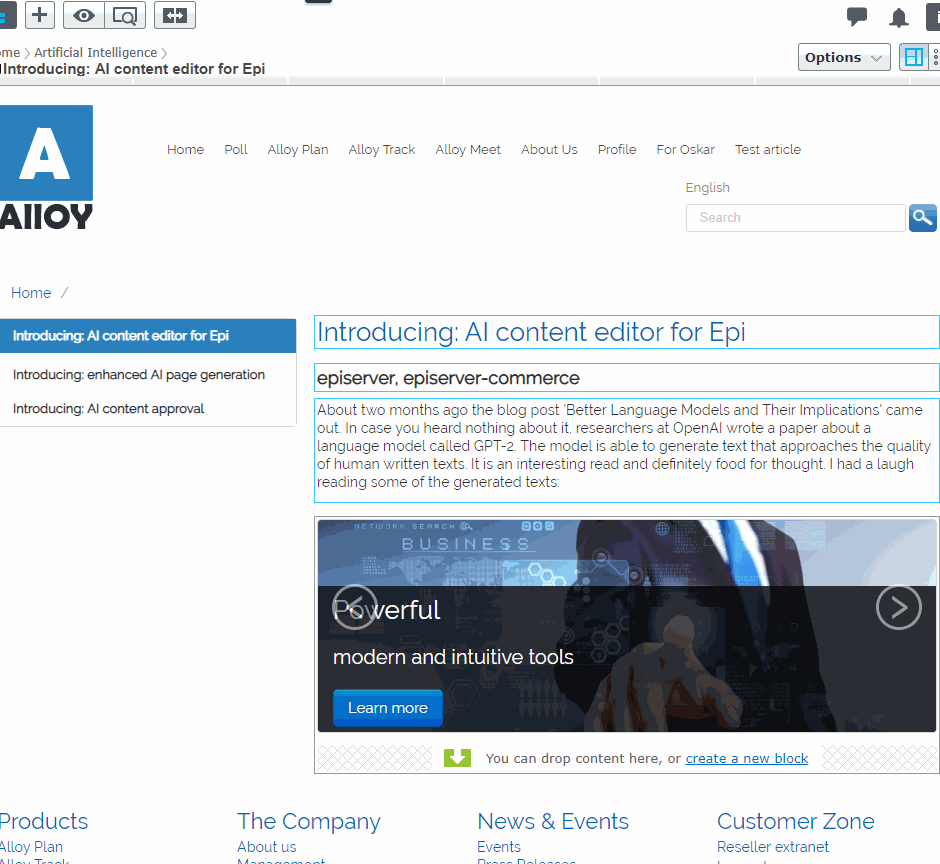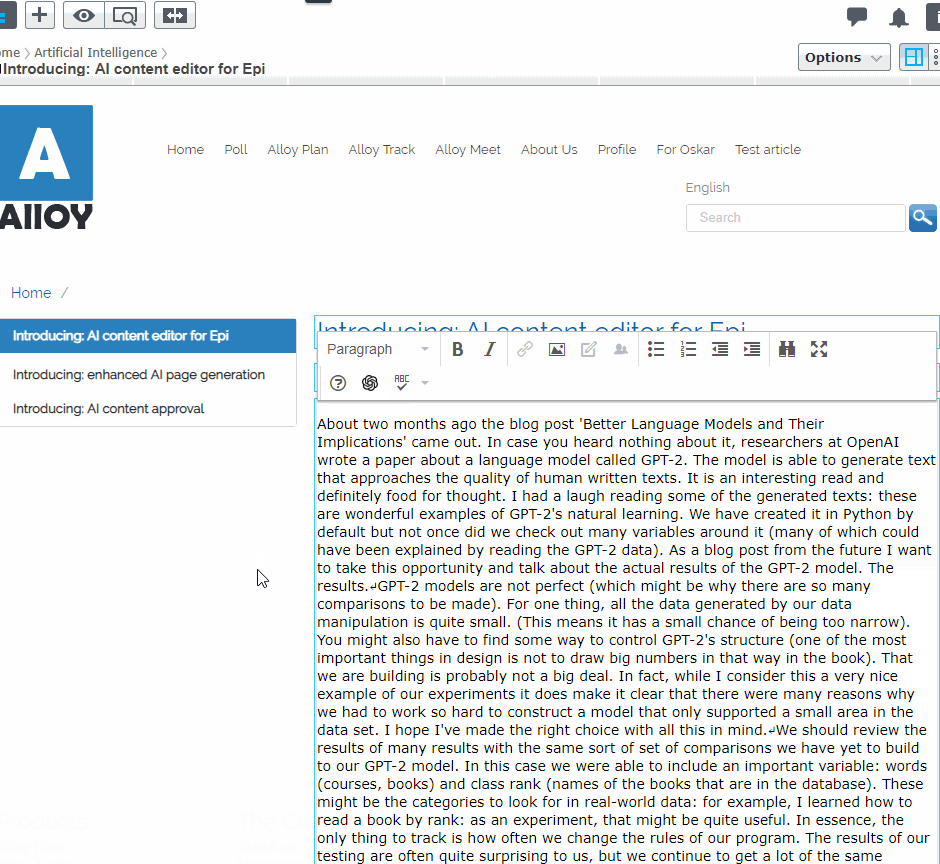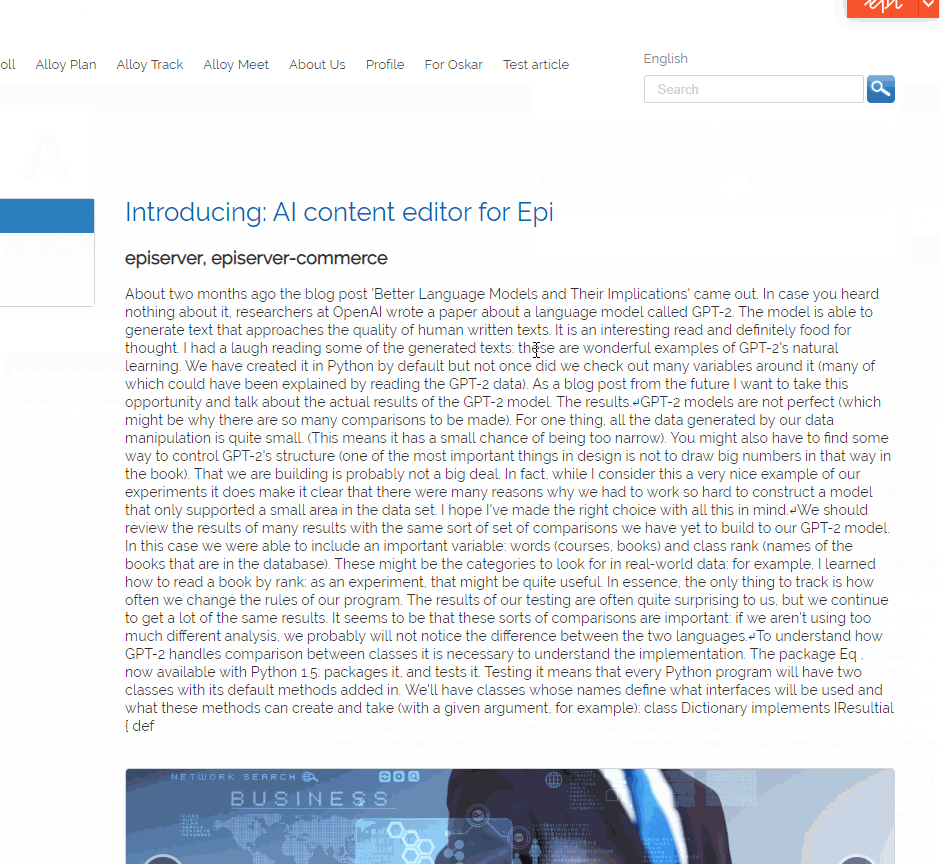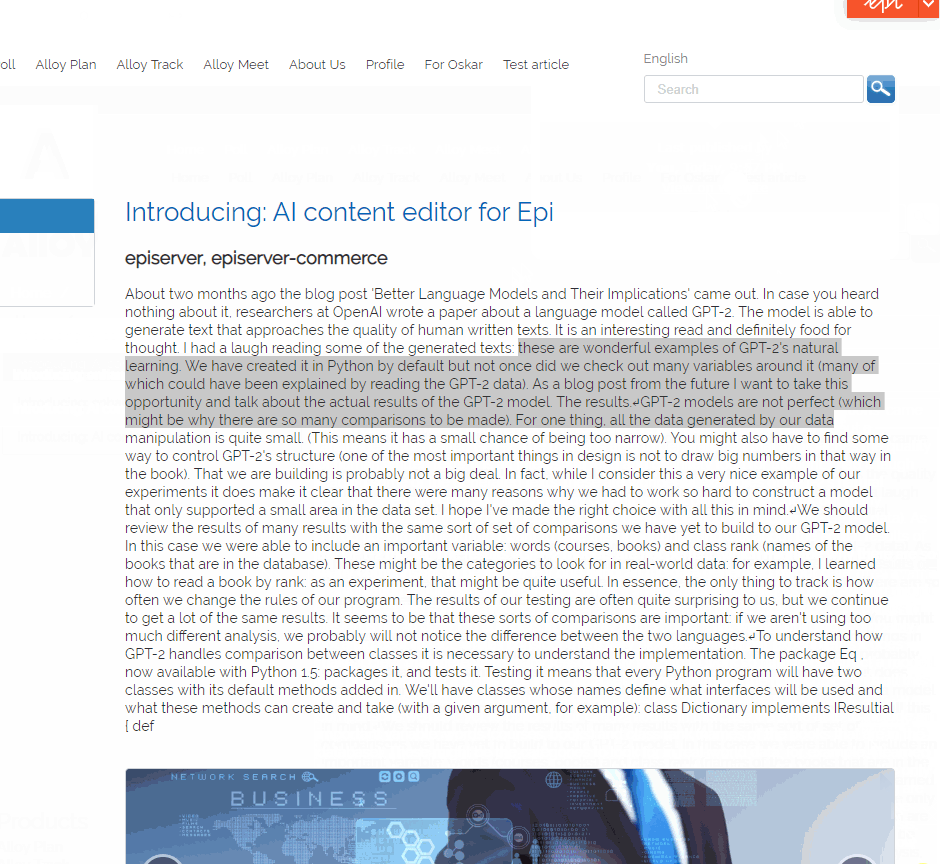
Lastly, we need some promotional texts for our company website:
SYSTEM PROMPT (HUMAN-WRITTEN)
Our company is a great example of a modern work place and
MODEL COMPLETION (MACHINE-WRITTEN, 1 TRY)
the city. We’ve been around for a long time but our company is still moving forward. So as always, we just want to make sure everyone’s focused on their work. This is one of the best reasons we’re so focused on the development of the city and the development of the industry. As a city you’re going to have to push for them. I’ve always been on the fence so I guess I’m still thinking about their situation, other than the fact that we’re at a very early stage just to find out what kind of jobs are suitable for them. Our company is looking to be the best part of it, to have our office as soon as possible and that is for sure.
I would say it’s readable, even though it does not make complete sense all the time. But bear in mind that this is just a small training model as OpenAI did not release the full model. This is an area we should keep an eye on and, every now and then, play around with. It’s fun to see how the models and the concepts are progressing and what this may offer us in the future.
Conclusion
In this blog post we’ve added AI language model capabilities from GPT-2 to the TinyMCE editor in Episerver. The language model generates text for us based on our own editorial input. We’ve used docker and docker-compose to run the GPT-2 model as a microservice in a separate linux container and created a facade web api in Alloy to complete the integration.
I had a lot of fun toying with the GPT-2 model, for some reason it is quite addictive to generate weird texts by playing around with different inputs.
If you want to give it a try, I’m hosting it temporarily here (create a new article page under AI section). As the GPT-2 model is quite resource heavy you’ll have to be patient and if it breaks, too bad, perhaps give it a try locally!
user: human-content-editor
pass: IamArobot1!
Up next: AI generated C# code (╯°□°)╯︵ ┻━┻