Part 5: Test method, Results and //TODO's
This is the second in a series of blog posts about typing accuracy.
- Part 1: Probable keyboard events
- Part 2: Implementing a touch model from scratch
- Part 3: Collecting touch data and re-executing touch events
- Part 4: Low end touchscreen limitations (Touching your keyboard with two fingers, no way!)
- Part 5: Test method, Results and //TODO’s
Test Methods
We compared the performance of four correction strategies. First we set a baseline by calculating the character error rate on the uncorrected input from the user (BASE). Then, we enable the Firefox OS built-in autocorrect algorithm (T1). With autocorrect enabled we test both the low-end device fix (T2) and the touch model (T3) separately. The last strategy, T4, is done with autocorrect, the low-end device fix and the touch model enabled. At the bottom of the page you can find the results per user.
To summarize:
BASE - Keyboard without autocorrect T1 - Autocorrect enabled T2 - Autocorrect and touch model enabled T3 - Autocorrect and low-end device fix enabled T4 - Autocorrect, touch model and low-end device fix enabled
The following figure shows the Character Error Rate (CER) averaged over all users.
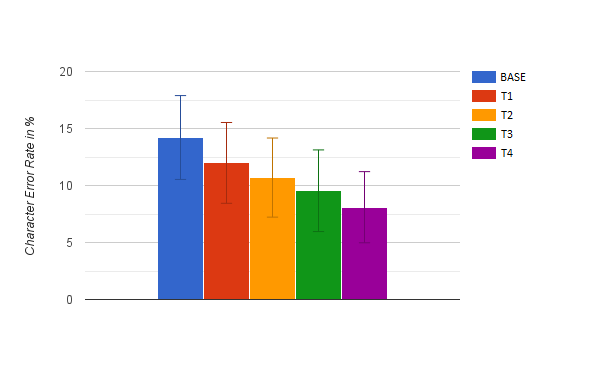
If we compare the results of the full model (T4) with the default autocorrect (T1), we see accuracy improvements for every user in our test set, with a relative improvement ranging between 17.19% and 72.74%!
Todo
- Build touch model while the user is typing. Instead of using pre-annotated data
- Use the touch model information during autocorrect (use probabilities for nearby keys)
- Improve autocorrect to detect separate words. Should be able to insert space
- Handle corrections even if user is typing a new word (fast type / slow device)
- Take context into account (n-gram model)
Results per user:
| User | BASE | T1 | T2 | T3 | T4 |
|---|---|---|---|---|---|
| 1 | 6.43% | 5.36% | 5.00% | 3.10% | 2.62% |
| 2 | 19.03% | 15.03% | 13.86% | 15.36% | 11.85% |
| 3 | 14.59% | 14.95% | 8.06 % | 13.15% | 7.45% |
| 4 | 20.47% | 16.99% | 16.71% | 14.07% | 14.07% |
| 5 | 8.52% | 5.21% | 1.58% | 5.05 % | 1.42% |
| 6 | 18.90% | 17.96% | 12.97% | 17.18% | 11.86% |
| 7 | 15.70% | 12.18% | 10.96% | 10.96% | 8.93% |
| 8 | 10.04% | 8.18% | 7.19% | 6.69% | 6.57% |
| mean | 14.21% | 11.98% | 10.70% | 9.54% | 8.10% |
| stdev | 5.30 | 5.11 | 5.16 | 5.00 | 4.50 |
| Margin | 3.68% | 3.54% | 3.58% | 3.47% | 3.12% |
| ci+ | 17.88 | 15.52 | 14.27 | 13.01 | 11.21 |
| ci- | 10.53 | 8.43 | 7.11 | 6.07 | 4.97 |